Um sistema de informação tem o objetivo de receber dados, processa-los e gerar informação.
O usuário "entra" com dados, o sistema "processa" esses dados e produz uma "saída".
Mas vamos com calma! Qual é a diferença entre dado e informação? De forma simplista, podemos dizer que o dado é um fato ou característica isolado referente a algum objeto, coisa ou entidade. Já a informação é um conjunto de dados relacionados. Por exemplo, uma pessoa possui nome, telefone, endereço entre outros dados. O nome é um dado, já o conjunto nome, telefone, endereço é uma informação.
Todo o processamento de dados é feita na memória principal do computador, porém como sabemos essa memória é volátil, ou seja, é apagada quando se desligar o computador e é aí que entra em cena os bancos de dados.
Você poderia dizer o seguinte: por que não gravar essas informações em arquivos? Bom, respondendo a essa pergunta com outra pergunta. Como organizar esses arquivos se o volume das informações for muito grande e com taxa de crescimento for constante? O banco de dados é a solução para o problema.
Armazenar informações organizadas e recuperá-las sem faltar um pedacinho sequer, sempre que necessário é a função principal dos bancos de dados.
Todo mundo que usa telefone costuma ter uma agenda telefônica. Nela cada amigo tem nome, endereço, número da linha, aniversário e nos tempos atuais e-mail e quando precisamos ligar para alguém, vamos à letra incial do nome e buscamos o número do telefone.
Essa "agendinha" expressa bem o conceito de banco de dados - um armazém de informações relevantes, organizadas de maneira coerente e lógica, que precisa ser recuperadas com frequência.
Esse universo envolve conceitos importantes que precisamos entender para torna-lo útil. Vamos a eles:
Sistema de gerenciador de banco de dados e Banco de dadosÉ importante não confundir os conceitos de sistema gerenciador de banco de dados e banco de dados.
O primeiro refere-se a programas que auxiliam ao usuário na tarefa de manipular e administrar os dados contidos em um banco de dados. Esses programas promovem os controles de acesso, redundância, integridade e o mecanismo de cópias de segurança dos dados presentes em um banco de dados.
Se você perguntar a um DBA com que banco de dados ele trabalha ele poderá responder que trabalha com o MySQL, Oracle, Sql server e por aí vai, porém se você fizer essa pergunta a um analista de sistemas ou a um analista de negócios, este poderá lhe responder que trabalha com o banco de dados do RH ou com o banco de dados acadêmico, por exemplo.
Modelagem de dados
A modelagem de dados é o processo pelo qual trabalham-se os dados de modo a promover estruturas de amazenamento estáveis. Esse processo se por meio da criação de modelos conceituais de entidade e relacionamento ou pela nomalização de dados, fazendo com que essas estruturas possam evoluir com o tempo, sem prejudicar o desenvolvimento de sistemas.
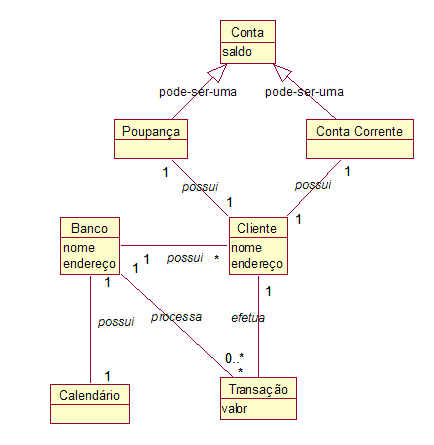
EntidadeEntende-se como um grupo de coisas semelhantes. Essas coisas podem ter uma existência física (pessoa, carro) ou abstrata (pedido, ordem de serviço). Cada entidade possui diversar instâncias do objeto que o representa.
Quando se transpõe a entidade para um modelo físico, criamos uma tabela. Já no modelo Orientado a objeto, temos o que chamamos de classe.
AtributoO atributo é um qualificador lógico de um objeto. É um dado e como tal, serve para descrever o caracterizar o objeto em questão.
Quando se transpõe para o modelo físico o atributo torna-se um campo. No modelo orientado a objeto é conhecido com propriedade ou atributo mesmo.
Tupla
Uma tupla é o conjunto de características do objeto. No modelo físico uma tupla é um registro presente em uma tabela. No modelo orientado a objetos, dizemos que esta é uma instância de um objeto.
TabelaA tabela é uma estrutura composta por registros compostos por linhas e colunas. A linha representa um objeto do mundo real e as colunas servem para qualificar esse objeto.
ChaveA chave é um qualificador único de um registro. É o campo escolhido para identificar exclusivamente um registro e por conta disso esse campo não poderá conter valores em branco ou repetidos.
Vamos imaginar qual atributo de uma pessoa seria a melhor opção para ser um chave. O campo nome com certeza não seria a opção a ser escolhida visto que existem pessoas com nomes homônimos. O CPF talvez seja um atributo candidato, pois é um documento obrigatório para uma pessoa adulta, porém esse documento não é obrigatório para crianças.
Nos casos em que nenhum dos atributos sejam qualificados para ser o campo chave do registro, deve-se criar um campo específico para isto (ex: matrícula). As chaves podem ser classificadas nos tipos abaixo:
- Primária - Classificam unicamente um registro. Toda tabela deve possuir uma chave primária.
- Estrangeira - Servem para relacionar as tabelas do banco de dados. Por exemplo temos duas tabelas: CLIENTE e NOTA_FISCAL. Cada tabela tem um chave primária , porém para relacionar essas tabelas a tabela nota fiscal deverá possuir a chave estrangeira CLIENTE que possuirá como valor um código de um cliente.
- Secundária - São os demais campos do registro que possui a função de subclassificar esses registros. É muito utilizado nos índices de uma tabela (falaremos sobre eles daqui à pouco).
RelacionamentoOs objetos do mundo real apesar de distintos guardam um certo grau de relacionamento com outros objetos.
Voltando ao exemplo do cliente/nota fiscal notamos que existe uma relação de interdependência entre essas duas entidades, ou seja, para emitirmos uma nota fiscal é necessária a existência de um cliente. A essa interdependência, damos o nome de relacionamento e este pode ser classificado de duas formas:
- Opcionalidade - indica se é obrigatória ou não a ocorrência ou indicação de um registro no outro.
- Cardinalidade - A cardinalidade indica quantas ocorrências de um registro podem se relacionar com outro registro.
Existem 3 tipos de cardinalidade:
- Um para um (1:1) - é quando cada tupla de uma entidade está relacionada a apenas uma tupla de outra entidade.
- Um para muitos (1:M) - é quando cada tupla de uma entidade pode estar relacionada a muitas tuplas de uma outra entidade.
- Muitos para muitos (M:M) - Neste caso várias tuplas de uma entidade podem estar relacionadas a várias tuplas de uma outra entidade.
Integridade referencialA integridade referencial é o mecanismo utilizado pelos gerenciadores de bancos com o objetivo de manter a consistência dos dados do banco.
Digamos que um usuário tente emtir uma nota fiscal com um código de cliente inexistente? Ou ainda apagar registro de um cliente que possui diversas notas fiscais cadastradas? Como ficaria a consistência dessas tabelas? Um bom SGBD deve garantir a integridade referencial do banco.
Restrições (Constraints)As restrições são utilizadas para melhorar a qualidade da informação guardada nas tabelas do banco. Já falamos sobre duas restrições: chaves primárias e estrangeiras, contudo existem outras restrições muito importantes:
- Nulos - servem para determinar se é permitido a inserção de um valorou não em um determinado campo;
- Exclusivos (unique) - servem para determinar se o campo pode ou não receber valores repetidos;
- Padrão - Serve para informar um valor padrão quando um valor não é informado pelo usuário;
- Domínio - Serve para limitar os valores a serem inseridos em um campo. Exemplo: O campo Sexo só pode receber dois valores (Masculino ou Feminino).
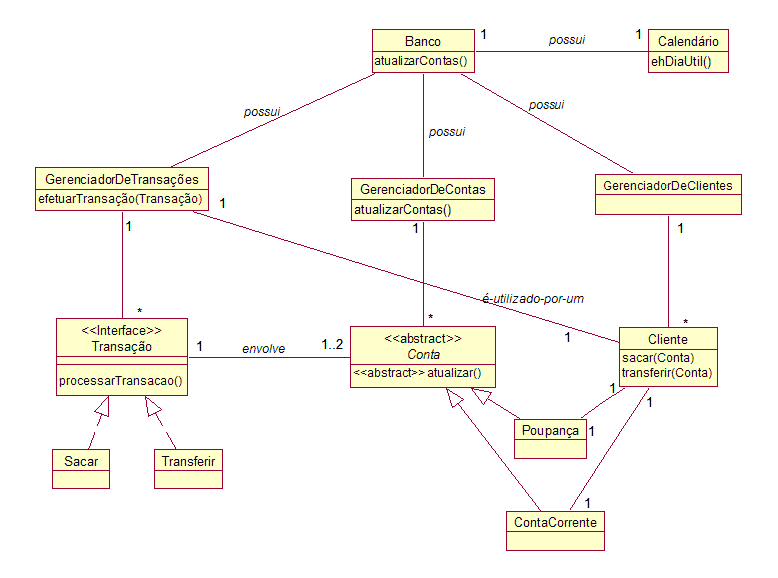
Transação
Sempre que ocorrer a alteração no conteúdo de uma ou mais tabelas de um banco de dados. Deste modo sempre que houver uma inclusão, alteração ou exclusão em um registro é gerada uma transação. O usuário ou o sistema gerenciador de banco de dados, nomento da operação, pode optar pela efetivação (COMMIT) ou pelo abandono da mesma (ROLL-BACK).
Procedimentos armazenadosSão pequenos códigos executados em um banco de dados que fim guardados para posterior utilização. São eles:
- Stored Procedures - código que realiza operações no banco de dados. Não retornam valor;
- Functions - idêntico a uma Stored procedures exceto por retornar valor;
- Triggers - são procedimentos disparados por eventos (a inclusão, alteração ou exclusão de um registro).
Algum desses conceitos são vistos como objetos em um banco de dados (tabelas, constraints, índices, stored procedures, usuários etc).
Bom, acho que com esses conceitos já dá para praticarmos um pouco de modelagem de dados, mas isso será assunto para outro post.


















{kind=link}
{kind=link}
{kind=link}